Why Local LLM?
身為一個合格的免費仔,當我想讓 LLM 幫我處理一些簡單的 tasks 時,肯定是不希望還要花錢打 api,心想反正都有 Llama, Qwen 等等模型可以使用,為什麼不直接在本地端跑跑看呢? 再者,近一年來小模型 (SLM) 的表現其實並不輸給前幾年的那些大模型 [1, 2, 3],而小模型的參數量基本上只需要一張 GPU 就可以 inference 的很快。因此我從去年開始使用 ollama 這個工具,讓我可以在 local 直接 serve 一個小模型。
Server Spec
- GPU: NVIDIA RTX 4000 ada sff
- GPU RAM: 20GB
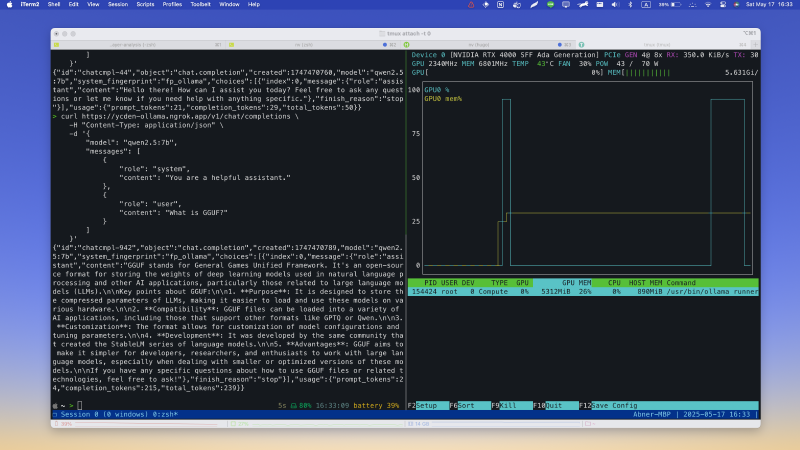
- Used LLM: Qwen2.5 7B [4]
- Used GPU Memory: 5.6GB
用 ollama 建立 Local LLM
會使用 ollama 是因為官方的 document 寫得很好、很簡單,api document 也很完整(相較於 vllm 啦,我自己也有稍微用過但偏麻煩就是了),以下會用 docker 起一個 ollama 來當作範例,因為我是 serve 在自己的伺服器上的,用 docker 會比較方便。
## cpu only
docker run -d -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
## with NVIDIA GPU
docker run -d --gpus=all -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
如果有要用 Nvidia GPU 的話記得先安裝好 NVIDIA Container Toolkit
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey \
| sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg
curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list \
| sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' \
| sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
sudo apt-get update
sudo apt-get install -y nvidia-container-toolkit
安裝好後記得讓 docker 用到 nvidia-container-toolkit 並重新啟動
sudo nvidia-ctk runtime configure --runtime=docker
sudo systemctl restart docker
這時候 docker ps 一下應該就會看到 ollama 這個 container 在跑了,這時候就可以 curl 一下看一切是否都正常
curl http://localhost:11435
如果出現 Ollama is running 代表沒問題了,接下來就可以來下載模型,所有可供下載的模型 ollama 都有放在 https://ollama.com/search 上,可以直接依照裡面的指示下載,這邊就不多說。
到此為止,就已經在 server 上成功把 ollama 跑起來了,接下來就是要透過 ngrok 把 localhost 連接到外網上,這樣在任何地方都可以使用。
Connect to LLM via Ngrok
一樣,這邊不多說 Ngrok 的安裝還是啥的
直接打開 ngrok.yaml 把 localhost 網址對應到 ngrok 的公開網址上就可以了
endpoints:
- name: ollama
url: your-ngrok-url
upstream:
url: http://localhost:11434
這時候回到 local,在 terminal 上直接 curl ngrok 的網址
curl https://your-ngrok-url/v1/models
這邊會需要加一個 v1 是因為 ollama api 本身是 OpenAI compatible (如果我的理解是對的話應該是因為 OpenAI api 是照著 REST API 在設計的)。如果有成功列出剛剛在 server 端下載的模型,就可以直接在 local 使用了。
References
[1] https://huggingface.co/spaces/TIGER-Lab/MMLU-Pro
[2] https://arxiv.org/pdf/2411.03350
[3] https://arxiv.org/pdf/2409.15790v1
[4] https://arxiv.org/pdf/2505.09388